Selecting content on a web page with CSS selectors
Overview
Teaching: 30 min
Exercises: 20 minQuestions
How can I select a specific element on web page?
What is a CSS Selector and how can I use it?
Objectives
Introduce CSS Selectors
Explain the structure of an XML or HTML document
Explain how to view the underlying HTML content of a web page in a browser
Explain how to run CSS Selector queries in a browser
Introduce the CSS Selector syntax
Use the CSS Selector syntax to select elements on this web page
Before we delve into web scraping proper, we will first spend some time introducing some of the techniques that are required to indicate exactly what should be extracted from the web pages we aim to scrape.
Matching patterns
A key part of web scraping is describing to the computer how it should find the content you seek. Several tools have been designed for succinctly describing patterns that can be matched to document structure so that selected content can be efficiently extracted. The most important for web scraping are:
- Regular expression: These select portions of strings of characters (e.g.
text, a URL). They can be used to identify, for instance, typical forms of
date (
yyyy-mm-dd,d/m/yyyy, etc.) or of an email address, or whether a URL is the kind of URL you want to download and scrape. - XPath: These specify parts of a tree-structured document, be it XML or HTML. They can be very specific about which nodes to include or exclude.
- CSS selectors: These serve a similar function to XPath, in selecting parts of an HTML document, but were designed for web development (for applying styles such as colour to parts of a document). As such, they are more popular, but are limited in what they can express relative to XPath. Every CSS selector can be translated into an equivalent XPath expression, but not vice-versa.
We focus on CSS selectors for their simplicity, although a parallel lesson covering XPath is available.
Markup Languages
When you view a page in your web browser, this usually involves downloading content encoded in HTML. The browser then renders this content visually.
XML and HTML are closely related markup languages. In fact HTML is like a dialect of XML specialised for structuring web pages. This means that they use a set of tags or rules to organise and provide information about their content. This structure helps to automate processing, editing, formatting, displaying, printing, etc. that information.
XML documents store data in plain text format, making it relatively easy to harness XML data without very specialised knowledge or tools. But the structure of XML demands techniques for pinpointing content within it.
XML and HTML
HTML and XML have a very similar structure, which is why XPath and CSS selectors can be used almost interchangeably to navigate both HTML and XML documents.
Structure of a marked-up document
An XML document follows basic syntax rules:
- An XML document is structured using nodes, which include element nodes, attribute nodes and text nodes.
- XML element nodes must have an opening and closing tag, e.g.
<catfood>opening tag and</catfood>closing tag. Everything between those tags is contained within the element. - XML tag names are case sensitive, e.g.
<catfood>does not equal<catFood>. - Within an element there may be other child elements. These must be properly nested (every child element that is opened must also be closed):
<catfood type="basic">
<manufacturer>Purina</manufacturer>
<contact>
<address class="USA"> 12 Cat Way, Boise, Idaho, 21341</address>
</contact>
<date>2019-10-01</date>
</catfood>
- Within an element there may also be text nodes.
Purinaand2019-10-01are both text nodes. Another text node contains the white space between<catfood>and<manufacturer>. - XML attribute nodes (like
typein<catfood>above) have a name, and a value that must be quoted.
Note that there may be multiple elements with a particular tag name:
<product>
<catfood type="basic"> ... </catfood>
<catfood type="basic"> ... </catfood>
<catfood type="premium"> ... </catfood>
</product>
Some of these rules are relaxed in HTML:
- tag and attribute names are case insensitive (
<catfood type="basic">equals<catFood Type="basic">) - some elements are closed automatically (e.g.
<img>cannot contain any other elements or text) - attribute values do not need to be quoted
HTML can nonetheless be represented as a tree of nodes.
Tree structure
A popular way to represent the structure of an XML or HTML document is the node tree, where each rectangle is a node:
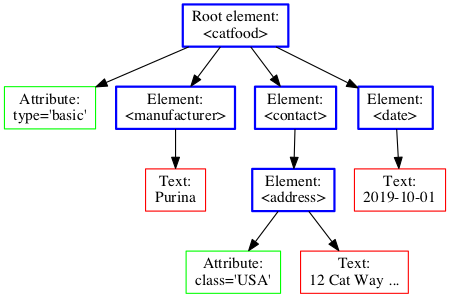
We use the terms parent, child and sibling to describe the hierarchical relationships between nodes:
- The top node is called the root (or root node).
<catfood>is the root here. - Every node has exactly one parent, except the root (which has no parent). The
<manufacterer>node’s parent is the<catfood>node. - An element (one kind of node) node can have zero, one or several children. Attribute and text nodes have no children.
<address>has two child nodes, but no child elements. - Siblings are nodes with the same parent.
- A node’s children and its children’s children, etc., are called its descendants. Similarly, a node’s parent and its parent’s parent, etc., are called its ancestors. Except for the root node, all nodes are descendants of the root node.
Common HTML elements
In HTML, the tag names aren’t usually as specific in their semantics as manufacturer or address. Here are some of the most common HTML elements:
| Tag name | What it is used for |
|---|---|
p |
A paragraph of text |
h1 |
A top-level heading |
h2, h3, … |
A lower-level heading |
li |
An item in a list |
img |
An image |
tr |
A row in a table |
td |
A cell in a table |
a |
A link |
div |
A block of space on the page (generic) |
span |
A portion of text on the page (generic) |
meta |
Information about the page that is not shown |
See the Mozilla Developer Network for a full listing.
CSS Selectors
Using CSS Selectors is similar to using advanced search in a library catalogue, where the structured nature of bibliographic information allows us to specify which metadata fields to query. For example, if we want to find books about Shakespeare but not works by him, we can limit our search to the subject field only.
When we use CSS Selectors, we do not need to know in advance what the content we want looks like (as we might with regular expressions, where specify the pattern of the data). Since HTML documents are structured as a network of nodes, CSS Selectors make use of that structure to navigate through the nodes and select the data we want. We just need to know which nodes in an HTML file contain what we want to extract.
A CSS Selector (as with an XPath selector) is, somewhat like a search query, a short piece of text that describes which nodes are sought. A CSS Selector can be evaluated on a document (or on each of many documents): the evaluator follows the instructions implied by the selector, finds the sought nodes in the document and returns them to the program that requested them.
Here are some examples of the sort of things one can express with CSS selectors (and XPath for comparison) based on the document fragments above:
| CSS selector | XPath expression | Description |
|---|---|---|
address |
//address |
Get every address element (and its contents) in the document |
catfood address |
//catfood//address |
Get every address element somewhere inside a catfood element |
catfood[type=basic] |
//catfood[@type='basic'] |
Get every catfood element that has a type attribute with value “basic” |
CSS selectors can only retrieve element nodes. Text and attributes need to be extracted outside of the CSS selector expression.
Finding elements with CSS selectors
CSS selector expressions consist of basic selectors which describe the properties of elements targeted for extraction (e.g. has tag name address is described as address). Sometimes we only want an element extracted if it appears in a particular context (e.g. appears somewhere inside a <catfood> element). We can describe valid contexts for the extracted elements by forming a basic selector for the context (catfood) and combining the selector for the context and the target (catfood address).
Common basic selectors are:
| Basic selector | Kind | Description |
|---|---|---|
* |
Universal selector | Matches all elements |
name |
Type selector | For any given name, matches all elements with that tag name. |
.name |
Class selector | Matches all elements whose class attribute includes the word name. |
#name |
ID selector | Matches all elements whose id attribute is exactly name. |
[attr] |
Attribute selector | Matches all elements having an attribute named attr. |
[attr=value] |
Attribute selector | Matches all elements having an attribute named attr whose value is value. |
[attr="value"] |
Attribute selector | Same. With quotes around value, it may contain spaces and punctuation. |
:nth-child(n) |
Pseudo-class | Matches all elements that are child number n (ignoring text and attribute nodes) under their parent. |
:nth-of-type(n) |
Pseudo-class | Matches all elements that are child number n of that same tag name under their parent. |
To express that an element must satisfy multiple properties, simply join them without a space in between. The example of catfood[type=basic] above combines a type selector and an attribute selector.
Required context can be expressed by combining a context selector (C) and a target selector (T) with special combinators:
| Selector combination | Name | Description |
|---|---|---|
C > T |
Child | Only match T when it is a child of an element matched by C. |
C T |
Descendant | Only match T when it is a descendant of an element matched by C. |
C + T |
Adjacent sibling | Only match T when it immediately follows C as C’s sibling. |
C ~ T |
Sibling | Only match T when it is a sibling of C (regardless of order). |
Note that C can be an arbitrarily complex selector, perhaps combining many basic selectors. T is a basic selector for the target.
Selecting the
<address>We repeat the above example document fragment:
<catfood type="basic"> <manufacturer>Purina</manufacturer> <contact> <address class="USA"> 12 Cat Way, Boise, Idaho, 21341</address> </contact> <date>2019-10-01</date> </catfood>With respect to this example, explain why each selector matches or does not match the
<address>node:
Selector Matches the <address>?addressYes AddressYes catfood addressYes catfood[type=basic] addressYes catfood[type=BASIC] addressNo! catfood[type=premium] addressNo catfood[type="basic"] addressYes catfood > addressNo catfood > * > addressYes catfood > :nth-child(2) > addressYes catfood > :nth-child(3) > addressNo catfood > :nth-of-type(1) > addressYes catfood > :nth-of-type(2) > addressNo catfood > manufacturer + * > addressYes catfood > date + * > addressNo catfood > date ~ * > addressYes catfood address.USAYes catfood address.usaYes catfood address[class=USA]Yes catfood address[class=usa]No! catfood address."usa"No (invalid) "catfood" addressNo (invalid)
Refer to the Mozilla Developer Network for a full listing of CSS selectors.
Drill common CSS selectors using the CSS Diner
The previous challenge illustrated understanding selectors, but it takes more practice to confidently compose and alter CSS selectors.
The CSS Diner is a fun way to practice writing CSS selectors. It shows XML code, with a corresponding display of food, and challenges you to select certain food, and only that food, by writing an appropriate CSS selector. In the pane on the right, it teaches you about expression syntax relevant to the current challenge.
Evaluating CSS selectors in a web browser
We will use the HTML code that describes this very page you are reading as an example. By default, a web browser interprets the HTML code to determine how to present to the various elements of a document, and the code is invisible. To make the underlying code visible, all browsers have a function to display the raw HTML content of a web page.
Display the source of this page
Using your favourite browser, display the HTML source code of this page.
Tip: in most browsers, all you have to do is do a right-click anywhere on the page and select the “View Page Source” option (“Show Page Source” in Safari).
Another tab should open with the raw HTML that makes this page. See if you can locate its various elements, and this challenge box in particular.
Another way to view the HTML node structure of the page is to right click the page and choose “Inspect” or “Inspect Element”. Note: this can differ from the HTML structure in the source code, because of how the browser processes the source HTML.
Developer tools in the Safari browser
If you are using Safari, you must first turn on the “Develop” menu in order to view the page source, and use the functions that we will use later in this section. To do so, navigate to Safari > Preferences and in the Advanced tab select the “Show Develop in menu bar” option.
The HTML structure of the page you are currently reading looks something like this (most text and elements have been removed for clarity):
<!doctype html>
<html lang="en">
<head>
(...)
<title>Selecting content on a web page with CSS selectors</title>
</head>
<body>
(...)
</body>
</html>
We can see from the source code that the title of this page is in a title element that is itself inside the
head element, which is itself inside an html element that contains the entire content of the page.
Say we wanted to tell a web scraper to look for the title of this page, we would use this information to indicate the
path the scraper would need to follow as it navigates through the HTML content of the page to reach the title
element. CSS selectors allow us to do that.
We can evaluate CSS selectors directly from within all major modern browsers, by using the built-in JavaScript console.
Display the console in your browser
- In Chrome, use the View > Developer > JavaScript Console menu item.
- In Firefox, use to the Tools > Web Developer > Web Console menu item.
- In Safari, use the Develop > Show Error Console menu item. If your Safari browser doesn’t have a Develop menu, you must first enable this option in the Preferences, see above.
Here is how the console looks like in the Firefox browser:

For now, don’t worry too much about error messages if you see any in the console when you open it. The console
should display a prompt with a > character (» in Firefox) inviting you to type commands.
The syntax to evaluate a CSS Selector on the current page within the JavaScript console is document.querySelectorAll("SELECTOR"). For example:
document.querySelectorAll("html > head > title")
If you enter this and press enter, it should return something similar to
NodeList [ <title ...> ]
The output can vary slightly based on the browser you are using. For example, Chrome will show [ where Firefox shows NodeList [. Both these symbols indicate that querySelectorAll returned a list of elements, even though there is only one <title> element in that list. We can extract the individual element by adding [0] to get the first element from the list:
document.querySelectorAll("html > head > title")[0]
Adding .innerText will retrieve the text from within the returned element. (Note that this .innerText notation looks deceptively similar to the class selector notation.)
document.querySelectorAll("html > head > title")[0].innerText
Output:
"Selecting content on a web page with CSS selectors"
Let’s look closer at this CSS selector: html > head > title. It can be thought of instructions for the web browser to find the <title> element. The <html> node is the root of an HTML document. We told the browser to:
html |
… navigate to the html node … |
> head |
… then to its child with tag name head … |
> title |
… then to its child with tag name title … |
Using this syntax, CSS selectors allow us to specify the exact path to a set of nodes.
Select the blockquote titled “Overview”
Write a CSS selector that selects the “Overview” box above, using a path of children from the root node, and try running it in the console.
Solution
document.querySelectorAll('html > body > div > blockquote:nth-of-type(1)')should produce something similar to
<- NodeList [ <blockquote.objectives> ]Alternatives include:
document.querySelectorAll('html > body > div > blockquote')[0]document.querySelectorAll('html > body > div > blockquote.objectives')
Nested elements
If we want to select all the blockquote elements visible on this page, we can write:
document.querySelectorAll('html > body > div > blockquote')
This produces an array of objects along the lines of:
<- Array [ <blockquote.objectives>, <blockquote.callout>, <blockquote.callout>, <blockquote.challenge>, <blockquote.callout>, <blockquote.callout>, <blockquote.challenge>, <blockquote.challenge>, <blockquote.challenge>, <blockquote.keypoints> ]
This selects all the blockquote elements that are children of the container <div>. If we want instead to select all
blockquote elements in this document, we can use:
document.querySelectorAll('blockquote')
This produces a longer array of objects:
<- Array [ <blockquote.objectives>, <blockquote.callout>, <blockquote.callout>, <blockquote.challenge>, <blockquote.callout>, <blockquote.callout>, <blockquote.challenge>, <blockquote.solution>, <blockquote.challenge>, <blockquote.solution>, … ]
Why is the second array longer?
If you look closely into the array that is returned by the
blockquoteselector above, you should see that it contains objects like<blockquote.solution>that were not included in the results of the first query. Why is this so?Tip: Look at the source code and see how the challenges and solutions elements are organised.
Class and ID filtering
We can use the class attribute of certain elements to filter down results. For example, looking
at the list of blockquote elements returned by the previous query, and by looking at this page’s
source, we can see that the blockquote elements on this page have different classes
(challenge, solution, callout, etc.).
To refine the above query to get all the blockquote elements of the challenge class, we can type
document.querySelectorAll('blockquote.challenge')
which returns
<- Array [ <blockquote.challenge>, <blockquote.challenge>, <blockquote.challenge>, <blockquote.challenge> ]
In principle, id attributes in HTML are unique on a page. This means that if you know the id
of the element you are looking for, you should be able to construct an expression that looks for this value
without having to worry about where in the node tree the target element is located.
Select the “Matching patterns” title by ID
Sometimes we can select an element by the order in which it appears, using selectors like
:nth-child(n)and:nth-of-type(n). But what if we want to match a particular element irrespective of order? Is there a different attribute that allows us to uniquely identify that title element?Write a CSS selector which extracts the “Matching patterns” title by its ID.
Tips:
- Look at the source of the page or use the “Inspect element” function of your browser to see what other information would enable us to uniquely identify that element.
- The syntax for selecting an element like
<div id="mytarget">is#mytarget.Solution
document.querySelectorAll("#matching-patterns")should produce something similar to
<- Array [ <h1#matching-patterns> ]
What makes a good selector?
Essential to web scraping is being able to select the set of elements you want, without selecting any additional elements. Many web scrapers are run periodically on web sites with changing data. One challenge is that the structure of that page can also change or vary across items being scraped.
A good selector may be characterised by:
- being specific: not capturing things you don’t need
- being robust to change: the selector should ideally still work if some basic things about the page structure change (e.g. an image is inserted; a field, such as an author’s name, is absent). If the selector breaks due to change it is better for it to extract nothing than to extract the wrong thing as it is easy to monitor how many selectors come back empty.
- being easy to read: if things are going to break or change, readable selectors help to avoid redesigning the selector from scratch.
All of these characteristics suggest preferring IDs and classes (and perhaps other attributes) where possible, and being judicious in choosing between a child or a descendant combinator.
Oftentimes, the elements we are looking for on a page have no ID attribute or other uniquely identifying features, so the next best thing is to aim for neighboring elements that we can identify more easily and then use sibling combinators to get from those easy-to-identify elements to the target elements.
Select this challenge box text
Using a CSS selector in the JavaScript console of your browser, select this paragraph and the rest of the contents of this challenge box.
Tips:
- The syntax to select the siblings of context elements is
context + target- Since you don’t have any basic selector attributes for the target, you might use the universal selector (
*)Solution
Let’s have a look at the HTML code of this page, around this challenge box (using the “View Source” or “Inspect Element” option) in our browser). The code looks something like this:
<!doctype html> <html lang="en"> <head> (...) </head> <body> <div class="container"> (...) <blockquote class="challenge"> <h2 id="select-this-challenge-box-text">Select this challenge box text</h2> <p>Using an CSS selector in the JavaScript console of your browser...</p> (...) </blockquote> (...) </div> </body> </html>We know that the
idattribute should be unique, so we can use this to select theh2element inside the challenge box:document.querySelectorAll("#select-this-challenge-box-text + *")[0]This should return something like:
<- NodeList [ <p>, <p>, <ul>, <p>, <blockquote.solution> ]Let’s walk through that syntax:
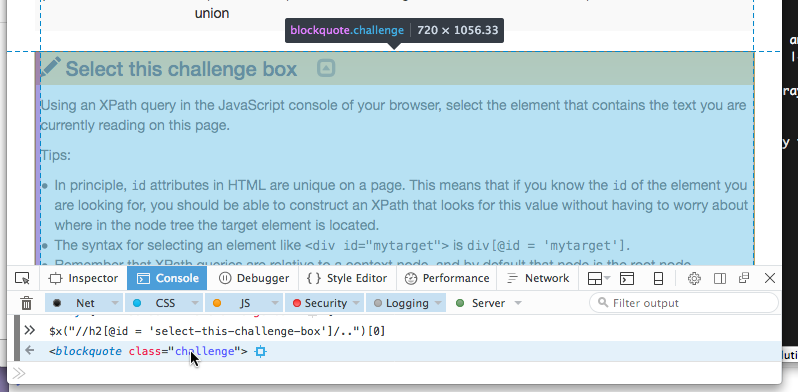
document.querySelectorAll("This function tells the browser we want it to execute an CSS selector . #...Find by ID (anywhere in the document)… + *Get all the siblings of the preceding context By hovering your mouse cursor over the object returned by your query in the console, your browser may helpfully highlight that object in the document, enabling you to make sure you got the right one:
Advanced :nth-... selectors
We presented the :nth-child and :nth-of-type selectors, but we only showed that you can place a number inside their parentheses, like :nth-child(2). However, you can put formulas in the parentheses:
:nth-child(2n)will select all even children:nth-child(2n+1)will select all odd children:nth-child(3n)will select every third child:nth-child(n+2)will select every child except for the first:nth-child(an+b)for any integers a and b will start selecting the _b_th child and select every _a_th child after that
:nth-last-child and :nth-last-of-type parallel the above pseudo-selectors, but their formulas match from last to first, rather than first to last.
Challenge: formulas in selectors
- Select the headline
<h2>of every second<blockquote>from the body of this page in the browser console.- Select the headline
<h2>of all but the first and the last<blockquote>from the body of this page in the browser console.Solution
document.querySelectorAll(".container > blockquote:nth-of-type(2n) > h2")document.querySelectorAll(".container > blockquote:nth-of-type(n+2):nth-last-of-type(n+2) > h2")Confirm that the right number of elements is returned with, for instance:
all_blockquotes_count = document.querySelectorAll(".container > blockquote > h2").length selected_blockquotes_count = document.querySelectorAll(".container > blockquote:nth-of-type(n+2):nth-last-of-type(n+2) > h2").length all_blockquotes_count - selected_blockquotes_countExpected result:
2
Limitations of CSS Selectors
A key limitation of CSS Selectors (prior to level 4) is that you cannot generally select an element based on what it contains. (This limitation my derive from the assumption that the author of a CSS selector was usually able to modify the markup to engineer simple selectors. This may be a reasonable assumption when selectors are used for styling a page or making it interactive.)
For example, using CSS3 selectors alone we cannot select a challenge box on the basis of its title <h2> having a specific ID.
CSS Level 4, which is (as of June 2017) a draft and not implemented in any major web browser may allow for:
/* May work in the future: */
document.querySelectorAll("blockquote.challenge > :matches(#select-this-challenge-box-text)")
Operating within these limitations, we are sometimes forced to use selectors only as an initial set of extractions, and then to navigate their surrounds with a general-purpose programming language. To extract the challenge box titled “Select this challenge box” in the web browser console, we can use parentNode in JavaScript:
document.querySelectorAll("#select-this-challenge-box-text")[0].parentNode
<- <blockquote class="challenge">...</blockquote>
XPath is able to select on the basis of descendants. Unlike CSS it is also able to:
- select just the first (or any other offset) of a set of elements. (
:nth-childand:nth-of-typecan only select the first with respect to a parent.) - select elements on the basis of the text they contain.
- return the value of an attribute on a matched element.
- return the text contained by matched elements.
These too require a general-purpose programming language to solve when using CSS selectors.
Tools to help composing CSS selectors
Viewing the HTML source of a page may help you design an appropriate selector. Another tool available to you is the “Inspector” or “Elements” tab of the developer tools in your browser. Right clicking an element on the displayed page and choosing “Inspect Element” will take you straight to that element’s HTML in its context. Then:
- Parts of the HTML can be shown or hidden by clicking the triangles on the left.
- Hovering your mouse cursor over an HTML element will highlight its position in the document.
- Above or below the HTML (depeding on web browser) you can see the list of elements (their tag names, IDs and classes) from the root to the selected element shown as basic CSS selectors.
Browser extensions such as Selector Gadget or CSS Selector Helper for Chrome may further assist in developing a specific selector.
Source vs computed DOM
What you see in the element / DOM inspector, and what
document.querySelectorAllevaluates CSS selectors on, need not be identical to what you see in View Source. The DOM (Document Object Model) is the version of the node tree computed by the browser after reading the HTML source, but also after running any scripts associated with the page. These scripts can modify the computed node tree in arbitrary ways, including loading content from other places and changing the page in response to interaction. Another reason the DOM may differ from the raw HTML is if the raw HTML is invalid: the web browser (or any HTML parser) needs to make interpretive decisions about where a missing closing tag of an element should be placed, or whether a closing tag lacking an opening tag like (</p>) should be treated as empty (<p></p>) or deleted altogether.Thus CSS selectors may give different results on the computed DOM than on the original HTML source.
Web scraping has traditionally been performed on the HTML source. Some scraper tools instead incorporate a web driver (basically a web browser with a computer operating it rather than a human) which runs all appropriate scripts and can even simulate interaction with the page.
References
- W3Schools: CSS Selectors
- W3Schools: HTML elements
- W3Schools: JavaScript HTML DOM Navigation
- Chrome devtools overview
Key Points
XML and HTML are markup languages. They provide structure to documents.
XML and HTML documents are made out of nodes, which form a hierarchy.
The hierarchy of nodes inside a document is called the node tree.
Relationships between nodes are: parent, child, descendant, sibling.
CSS selectors are constructed by specifying properties of the targets combined with properties of their context.
IDs, classes and tag names should be preferred as properties for extraction.
CSS selectors can be evaluated using the
document.querySelectorAll()function.