What is web scraping?
Overview
Teaching: 10 min
Exercises: 0 minQuestions
What is web scraping and why is it useful?
What are typical use cases for web scraping?
Objectives
Introduce the concept of structured data
Discuss how data can be extracted from web pages
Introduce the examples that will be used in this lesson
What is web scraping?
Web scraping is a technique for targeted, automated extraction of information from websites.
Similar extraction can be done manually but it is usually faster, more efficient and less error-prone to automate the task.
Web scraping allows you to acquire non-tabular or poorly structured data from websites and convert it into a usable, structured format, such as a .csv file or spreadsheet.
Scraping is about more than just acquiring data: it can also help you archive data and track changes to data online.
For example:
- Online stores will periodically scour the publicly available pages of their competitors, scrape item names and prices and then use this information to adjust their own prices.
- Marketing databases may be compiled by scraping contact information such as email addresses.
Applications of scraping in research and journalism may include:
- tracking trends in the real estate market by scraping data from real estate web sites
- collecting online article comments and other discourse for analysis (e.g. using text mining)
- gathering data on membership and activity of online organisations
- collecting archives of reports from many web pages
The practice of data journalism, in particular, relies on the ability of investigative journalists to harvest data that is not always presented or published in a form that allows analysis.
Behind the web’s facade
At the heart of the problem which web scraping solves is that the web is (mostly) designed for humans. Very often, web sites are built to display structured content which is stored in a database on a web server. Yet they tend to provide content in a way that loads quickly, is useful for someone with a mouse or a touchscreen, and looks good. They format the structured content with templates, surround it with boilerplate content like headers, make parts of it shown or hidden with the click of a mouse. Such presentation is often called unstructured.
In other cases, the data presented in a web site has been edited or collated manually, and does not present some underlying structured database.
Web scraping aims to transform specific content in a web site into a structured form: a database, a spreadsheet, an XML representation, etc.
Web designers expect that readers will interpret the content by using prior knowledge of what a header looks like, what a menu looks like, what a next page link looks like, what a person’s name, a location, an email address. Computers do not have this intuition.
Web scraping therefore involves:
- telling a computer how to navigate through a web site to find required content (sometimes called spidering); and
- providing patterns with which the computer can identify and extract required content.
Not web scraping: structured content on the web
There are, however, many forms of structured content on the web, which are (ideally) already machine-readable (although they may still need transformation to fit into your database/format of choice). These include:
- Data downloads: some web sites provide their content in structured forms. Some names for data formats include Excel, CSV, RSS, XML and JSON.
- APIs: many major sources and distributors of content provide software developers with a web-based Application Programming Interface to query and download their often dynamic data in a structured format. APIs tend to differ from each other in design, so some new development tends to be required to get data from each one. Most require some authentication like a username and password before access is granted (even when it is granted for free).
- semantic web knowledge bases: web sites providing structured knowledge, of which WikiData is a good example. These tend to be structured as OWL ontologies, and can often be queried through SPARQL endpoints or downloaded as large data collections.
- microformats: some web sites may overlay their visual content with specially schematised labels for certain kinds of knowledge, such as publication metadata (title, author, publication date), contact details or product reviews. While web sites using microformats are by far in the minority, where they are, specialised extraction tools do not need to be developed.
Before scraping a web site, it is always a good idea to check whether a structured representation of the same content is provided. Choose the right (i.e. the easiest) tool for the job.
- Check whether or not you can easily copy and paste data from a site into Excel or Google Sheets. This might be quicker than scraping.
- Check if the site or service already provides an API to extract structured data. If it does, that will be a much more efficient and effective pathway. Good examples are the Facebook API, the Twitter APIs or the YouTube comments API.
- For much larger needs, Freedom of Information requests can be useful. Be specific about the formats required for the data you want.
Not web scraping: information extraction
We are also not including tasks that find content in free text. Such tasks, known by the name information extraction may seek a list of all organisations mentioned, or may try to identify mentions of business acquisitions and the companies involved from text. Related technology in text interpretation may try to determine if an author used positive or negative language. Related technology in information extraction may aggregate content found in differently formatted tables across many web sites (or academic papers).
These are real technologies, but not within scope of web scraping. In contrast to these, web scraping usually expects content to be consistently formatted, and extractable with very high precision (the extracted content is very clean of errors) and recall (the extracted content is complete from the pages visited).
Example: a database of UN Security Council Resolutions
In this lesson, we will extract the history of resolutions made by the United Nations Security Council (UNSC) as found on its web site. Each year from 1946 to now has its own page on which resolutions from that year are posted in a tabular form. Our task is to build a system which extracts a spreadsheet in comma-delimited (CSV) format with rows like:
date,symbol,title,url
…
2010,S/RES/1942 (2010),Côte d'Ivoire,http://www.un.org/en/ga/search/view_doc.asp?symbol=S/RES/1942(2010)
2010,S/RES/1941 (2010),Sierra Leone,http://www.un.org/en/ga/search/view_doc.asp?symbol=S/RES/1941(2010)
…
1962,S/RES/174 (1962),Admission of new Members to the UN: Jamaica,http://www.un.org/en/ga/search/view_doc.asp?symbol=S/RES/174(1962)
…
This comma-delimited format lists each resolution on a separate line, with the fields “date”, “symbol”, “title” and “url” separated by commas (“,”).
Looking at the web site, it appears quite close to this format already: each page, such as the one for 1962 includes a table with a row for each resolution.
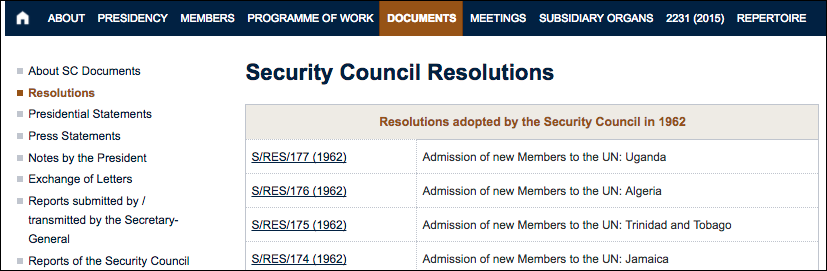
The last row excerpted above (and also shown in the intended CSV output) is encoded in HTML as:
…
<tr>
<td><a href="/en/ga/search/view_doc.asp?symbol=S/RES/174(1962)">S/RES/174 (1962)</a></td>
<td>Admission of new Members to the UN: Jamaica</td>
</tr>
…
When looking at such pages, we can see that the columns aren’t labelled. We are expected to understand that the left column is some reference identifier or symbol for the resolution, and the right column is a title or topic. Thus we interpret the visual presentation of the data, relying on our background knowledge. When we do not care to navigate around the site, we similarly are able to identify the navigation menus on the left and at the top and ignore it. Computers cannot make such interpretations unassisted.
Structured vs. unstructured data
When presented with information, human beings are good at quickly categorizing it and extracting the data that they are interested in. For example, when we look at a magazine rack, provided the titles are written in a script that we are able to read, we can rapidly figure out the titles of the magazines, the stories they contain, the language they are written in, etc. and we can probably also easily organize them by topic, recognize those that are aimed at children, or even whether they lean toward a particular end of the political spectrum. Computers have a much harder time making sense of such unstructured data unless we specifically tell them what elements data is made of, for example by adding labels such as this is the title of this magazine or this is a magazine about food. Data in which individual elements are separated and labelled is said to be structured.
The task
Our task is to merge the data from all the UNSC resolution pages into a single, consistent and machine-readable format that will allow us to:
- count and plot how many resolutions were passed each year
- count and plot how many pertained UN membership vs. security motions
- search for resolutions pertaining to particular countries’ names
- divide the statistics by geopolitical region (e.g. South America vs. East Asia)
- periodically update our database as long as the web site maintains its current format
(We could potentially further enrich the database with the full digitised text of the resolutions, but this would require performing Optical Character Recognition since most of the resolutions are presented as PDFs of scanned paper prints. We leave this as a further exercise for the student!)
How can we do this?
We could try copy-pasting the table for each year into a spreadsheet, but this can quickly become impractical when faced with a large number of years, and wanting to collect updates frequently. Another resource may have a multitude of pages (monthly or weekly records, perhaps) for similar archives.
Fortunately, there are tools and techniques to automate at least part of the process, known as web scraping. Web scraping typically targets one web site at a time to extract unstructured information and put it in a structured form for reuse.
Assuming that many other sites, or UN agencies, archive reports and resolutions through similar web pages, the same techniques (although perhaps not the same exact piece of software) can be used to extract their data.
Scraping robustly
This is but one instance of web scraping. It is interesting because the data is apparently not already contained in a database on the UNSC web site. When we come to scrape it, we will identify a number of quirks and inconsistencies that are endemic to manually edited sites. However, quirks may also occur in web sites backed by databases. For instance, there may be multiple types of product and each is presented differently; or some fields appear and disappear depending on the object; or you want to be able to periodically update the scraped data, but the web site changes its design altogether. Among the major challenges in designing a web scraper is building a system that is robust to variation, or where it is easy to diagnose that the web scraper has broken.
In this lesson, we will continue exploring techniques to extract the information in the UNSC resolutions archive. But before we launch into web scraping proper, we need to look a bit closer at how information is organized within an HTML document and how to build queries to access a specific subset of that information.
Tools and techniques for scraping
A number of tools have been developed to help build web scrapers. These differ in capability or expressiveness, and in their usability without programming. Several of the available tools are associated with services which host the scraper and run it for a fee. Our workshop emphasises core technologies and concepts for spidering and for extracting content from page structure, while trying to focus on free open-source tools.
References
Key Points
Humans are good at categorizing information, computers not so much.
Often, data on a web site is not properly structured, making its extraction difficult.
Web scraping is the process of automating the extraction of data from web sites.