Visual scraping using browser extensions
Overview
Teaching: 45 min
Exercises: 25 minQuestions
How can I get started scraping data off the web?
How can I use CSS selectors to precisely select what data to scrape?
Objectives
Introduce the Chrome Web Scraper extension.
Practice scraping data that is largely well structured, merging data from many pages.
Use CSS selectors to refine what needs to be scraped when data is less structured.
An introduction to visual scrapers
Visual scrapers are tools in which the user can visually select the elements to extract, and the logical order to follow in performing a sequence of extractions. They require little or no code, and assist in designing XPath or CSS selectors.
Visual scraping tools vary in how flexible they are (in comparison to the full expressiveness of coding your own), how easy to use, to what extent they help you identify and debug scraping problems, how easy it is to keep and transfer your scraper to another service, and how costly the service is. Many visual scrapers require you to pay for their services beyond a small number of trial extractions, may only store your data for a limited time, and may not provide a way for you to take your scraper off their site for reuse or extension. Some do not allow you to write your own XPath / CSS / regular expression selectors; some only support CSS or XPath but not the other.
Why we chose the Web Scraper extension
In designing this lesson, we have chosen to emphasise free solutions that give you ultimate control of the scraper and its data. As of June 2017, we have only found a few visual scraping tools that are Free Open-Source Software, including webscraper.io’s Web Scraper Chrome extension, David Heaton’s Scraper Chrome extension and Portia. While there are numerous advantages to Portia, we found it relatively difficult to install and ran into bugs (though it calls itself a Beta, so bugs are to be expected). Scraper is limited to extracting data from a single page, and also had some issues when we tested it. In comparison to refined commercial tools, Web Scraper’s user experience leaves much to be desired, but it is a flexible tool (although it does not support XPath) and a useful introduction to scraping without coding.
See Setup for instructions on installing the Web Scraper browser extension.
Using the Web Scraper Chrome extension
We are finally ready to do some web scraping. Let’s go to the index of UNSC resolutions in our Chrome browser.
To use the Web Scraper, we need to open the Developer Tools as in the previous episode (right click on the page and choose Inspect Element is often the simplest way in). In the Developer Tools, you should find a tab entitled Web Scraper. Activate the tab, click Create new sitemap below it and then Create sitemap, as numbered in the following:
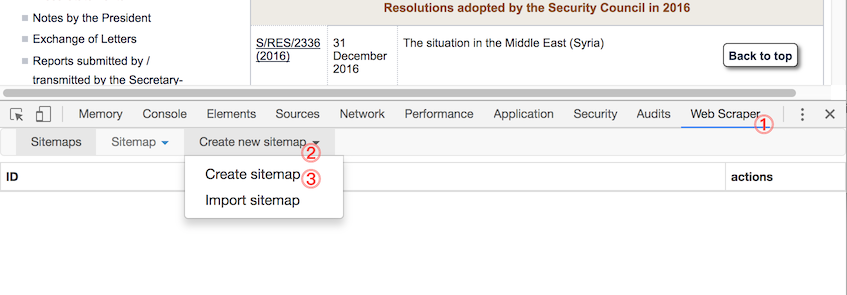
(If the Developer Tools were not docked at the bottom of your web browser window (usually they are), you will need to dock them there.)
Sitemap is essentially the Web Scraper extension’s name for a scraper. It is a sequence of rules for how to extract data by proceeding from one extraction to the next. We’ll name the sitemap “unsc-resolutions”, set the start page as http://www.un.org/en/sc/documents/resolutions/, and click Create Sitemap.
Before we start constructing the sitemap, let’s try to understand the structure of a complete sitemap.
The selector graph: here’s one we made earlier
A Web Scraper sitemap consists of a collection of selectors each of which may identify:
- specific content to extract;
- elements of the page containing content to extract (e.g. an entry in a catalogue, each of which contains multiple specific pieces of content, like model, brand, price, etc.); or
- a link to follow and continue scraping from.
Each selector (except a special one called _root) has a parent selector defining the context in which each selector is to be applied. For example, the following shows a visual representation (“Selector graph”) of the final scraper we will build for the UNSC resolutions:
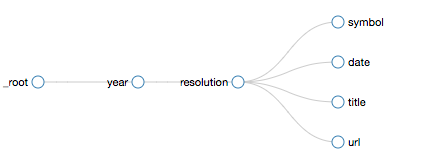
Here _root represents the starting URL, the home page of UNSC resolutions. From it, the scraper gets a link to each year page. For each year, it extracts a set of resolution elements. For each resolution element, it extracts a single symbol, a single date, a single title, and a single url.
Since the years are linked from the start page, _root is the parent of the year selector. Since resolutions can only be extracted once on a year page, year is the parent selector of resolution. Similarly, since a symbol is extracted for each resolution, resolution is the parent selector of symbol. Etc.
Navigating from root to year pages
At this point, we have the Web Scraper tool open at the _root with an empty list of child selectors.

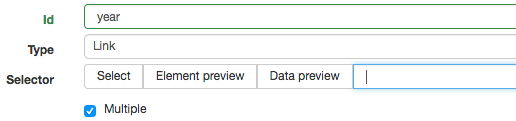
Click Add new selector. We will add the selector that takes us from the index to each year page. Let’s give it the id year. Its type is Link. We want to get multiple year links from the root, so we will check the Multiple box below.
Under Selector, there are tools for building a CSS selector. Rightmost (highlighted blue below) is a text box where we can enter a CSS selector. The Select button gives us a tool for visually selecting elements on the page to construct a CSS selector. Element Preview highlights on the page those elements that would be selected by the specified selector. Data Preview pops up a sample of the data that would be extracted by the specified selector.
Let’s start by entering the selector a, which will match all <a> (hyperlink) elements in the page. Click Element Preview and all links in the page you are viewing will blush. (You must be talking about them!) Click Data Preview and we’ll see that from the set of links we can scrape a table consisting of the text and the link URL (plus a couple of administrative details).
We only want to capture year links, not all links, in the page. We could construct the CSS selector by inspecting the page’s source or element tree. Instead we will use Web Scraper’s Select feature.
Click Select. A small selection tool will appear above the Developer Tools, hovering over the UNSC page. Hover your mouse over one of the year links and it should be highlighted in green:
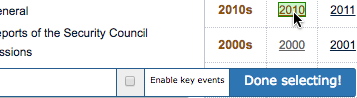
Click one of the year links. A very specific CSS selector such as tr:nth-of-type(3) td:nth-of-type(1) a will be filled in on the left of the selection tool, and the year you clicked will be reddened to indicate that it is included in the proposed selector. Click one of the other (unselected) year links and the CSS selector should be adjusted to include it. Keep clicking years until all of them are selected. (If you make a mistake, or if – unfortunately – Web Scraper refuses to let you select all the links you desire, click the Select button in the main Web Scraper tool to start again.) The final selector should be td a, which will select every link (<a>) element anywhere inside a table cell (<td>) element anywhere in the page. Click Done Selecting and the identified selector will appear in the text box where we entered a before.
We do not require the scraper to delay before selecting each year, nor do we need to change the parent selector (_root is correct). So click Save Selector. This returns us to the list of selectors that are children of _root. Now we have one: the year selector.
Running the scraper
What happens if we run the scraper as it is now? To do so, click Sitemap (unsc-resolutions) to get a drop-down menu, and click Scrape as shown:
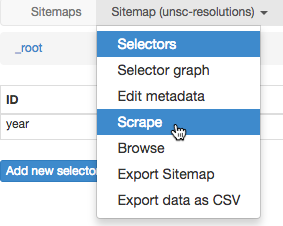
The scrape pane gives us some options about how slowly Web Scraper should perform its scraping to avoid overloading the web server with requests and to give the web browser time to load pages. We are fine with the defaults, so click Start scraping. A window will pop up, where the scraper is doing its browsing. The list of year links will be scraped, and the window will close, as the scraping is complete! We can see a table of year and year-href values to show us that our very simple scraper has worked! The Export data as CSV entry on the drop-down menu will even bring the scraped data into Excel.
Click Sitemap (unsc-resolutions) to get the drop-down menu again, and Selectors will return you to the root selectors. Note that you can click Data preview for a quick and dirty alternative to actually running the scrape.
A selector for resolutions
Clicking the year ID will take you to its child selectors, i.e. the things to scrape on every year page; there are none. Clicking year will not take you to an example year page. But since its child selectors only apply in the context of each year page, you will have to click a year link yourself – say, 2016 – to design year’s child selectors.
We will now create a selector which captures each element containing data for a single resolution, i.e. each selected item should be a row of the table.
- id:
resolution - type: Element
- multiple: checked
- parent selector:
year - selector: ???
Note that here we want to select an Element type, as we want to be able to further scrape within each of the resolution elements; we don’t just want its text, for instance.
The selector for resolutions is, in this case, a bit tricky, for two reasons:
- As you can see by inspecting the page source, each resolution is presented in a table row
<tr>element. However: the table title is also a row, but doesn’t contain resolution data! So a simple CSS selector liketrwhich captures all table rows will not suffice. We cannot use CSS2 Selectors to say that we’d only like rows containing more than one<td>cell (though we could do this kind of thing with XPath). We can, however, use CSS2 selectors to get all but the first using an advanced:nth-childor:nth-of-typeselector. - We want each selected element to contain all the data for a single resolution, not just its title, for instance. Using the visual Select tool, it is hard to select a row in entirety, as clicking anywhere in a table will select a cell
<td>element or something within it, rather than the row as a whole. To facilitate selecting the whole row, the Select tool has a feature where pressing P on your keyboard will change the proposed selector so that it selects the parents of the currently selected elements. So if you select a cell from the table and hit P it should select the row.
Challenge: Construct a selector to get all resolution rows
Using either the Select tool (and its P feature), or by manually composing an advanced (formula-based)
:nth-of-typeCSS Selector, capture all and only resolution rows from the page.Solution
One solution CSS selector is
tr:nth-of-type(n+2). To get this with the visual Select tool:
- Click Select to launch the tool
- Click the top cell of the table with a resolution title in it. A selector such as
tr:nth-of-type(2) td:nth-of-type(3)should appear.- Press P on your keyboard. The selector should now become something like
tr:nth-of-type(2).- Click on another row of data. The selector should now be
tr:nth-of-type(n+2). Confirm that all the rows we want are included. Click Done Selecting.
Save selector!
The data for each resolution
We finally need to add child selectors of the resolution selector. Click the row for the resolution selector to see its children. There are currently none. Let’s make some for symbol, url, date and title.
Click Add new selector, and enter:
- id:
symbol - type: Text
- selector:
td:nth-of-type(1) - multiple: not checked
- parent:
resolution
Note that we do not check multiple because, although there are multiple on the page, we only want one per resolution, being the context (parent) of this selector. Note, similarly, that using the Select tool only allows us to select from within the first matching resolution element. Save selector!
Add another:
- id:
symbol - type: Element attribute (although you could instead use Link)
- selector:
a - multiple: not checked
- attribute name:
href - parent:
resolution
Using the Element attribute type allows us to get the value of the href attribute on each <a> element in the row. The href attribute is where the link target is stored. For example, one HTML fragment looks like:
<td class="class"><a href="http://www.un.org/en/ga/search/view_doc.asp?symbol=S/RES/2335(2016)">S/RES/2335 (2016)</a></td>
We should at this point use the Data Preview feature to see what will be extracted. For instance, click year:
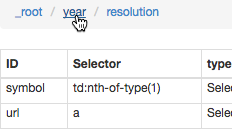
Then click Data Preview on the resolution row to see the following:
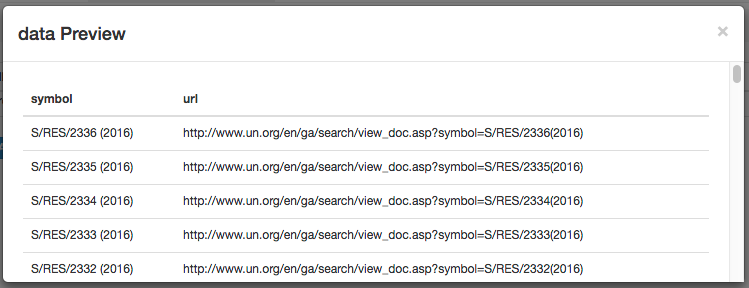
(Note that we intentionally did not click _root for data preview, because the data preview feature can only show data extracted from the current page. The current page is a resolution page, while _root’s child selectors only work on the index page.)
Challenge: add new selectors for
dateandtitleAdd new selectors under
resolutionfor a resolution’s title and date fields.Solution
The
dateselector could be:
- id:
date- type: Text
- selector:
td:nth-of-type(2)- multiple: not checked
- parent:
resolutionThe
titleselector could be:
- id:
date- type: Text
- selector:
td:nth-of-type(3)- multiple: not checked
- parent:
resolution
Improving open-source tools
We feel that some of this interface is quite unintuitive. If you have specific constructive critique for how the Web Scraper tool can be improved, you should:
- Look at the list of issues for the project and search through it to see if a similar suggestion has already been made. Perhaps use a GitHub account to indicate your support for that suggestion.
- Create a new issue to suggest a change or highlight a problem.
- Consider assisting in the development of the extension, if you have sufficient experience with the technologies used (JavaScript, HTML, CSS, etc.).
More data previews and some fixes
Inspecting the Data Preview on resolution again, things look okay.
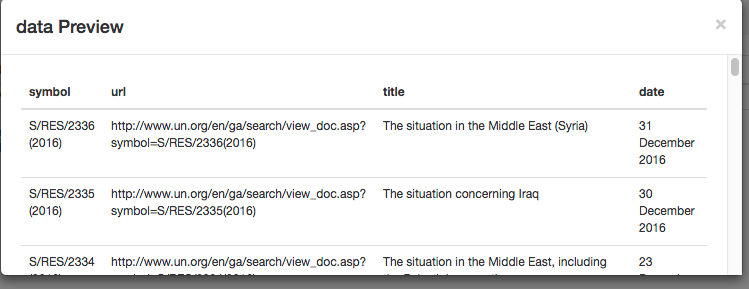
Or at least they do for 2016.
Challenge: using Data Preview to identify this scraper’s failures
Now run the Data Preview on the page for 1999. There the date column does not exist. What does the scraper get wrong?
Solution
We note that the date column doesn’t exist, the
resolutionData Preview shows us some issues.
dateis filled with titlestitleis filled withnullurldoesn’t havehttp://...at the front
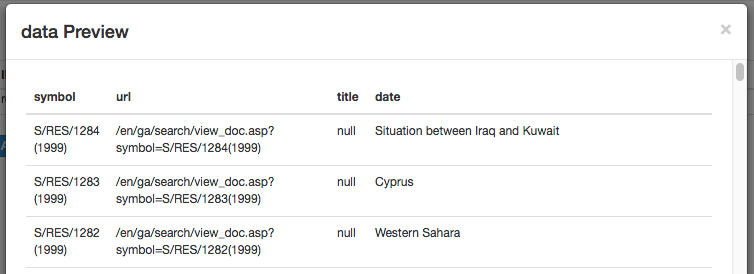
A visual scraper may help you build the CSS selector for a set of elements on a page, but that CSS selector might not be the best match for all pages you wish to scrape. (But most web sites aren’t this quirky, either!)
We need to get a bit creative and use advanced techniques to handle pages with and without a date column, and the variation in URL format. Visual scraping may handle variation in the page structure poorly, which motivates having more control over your scraper by coding it up as we will in the next episode.
Possible solutions using the Web Scraper extension:
- We can more-or-less fix the
urlissue by telling Web Scraper to extractsymbolas as Link (not a Text) with theaselector. This will extract the full (resolved) URL of the link as well as the link text, in two separate columns of the extracted data. We can then delete theurlselector. - For the
titlewe can change the selector fromtd:nth-of-type(3)totd:nth-last-of-type(1), as it is always the last column but not always the third. - And we can fix (hackily!) the
dateissue by requiring that the date text have a certain form. We can use regular expressions: enter^[0-9].*[0-9]$in the Regex field. This matches only text which begins with a digit and ends with a digit. Hopefully (but we should check after the fact) this will not match any titles.
Run it!
Choose Scrape from the drop-down menu and Start Scraping.
A window pops up where Web Scraper is doing its work: starting at the index then proceeding to each page of resolutions in turn. It will take around 5 minutes to run. It should be possible to Browse (under Scrape in the drop-down menu) the data being collected during scraping.
You can also save a machine readable copy of your scraper details by selecting Export Sitemap and copying the code there to a file.
When it is finished, Export data as CSV and view the data in spreadsheet software such as Excel or Google Sheets.
Extension challenge: count how many resolutions there are per year
Use spreadsheet software to count the number of resolutions per year. Are any numbers surprising?
Hint: consider using a Pivot Table, and then a bar chart of the counts.
Solution
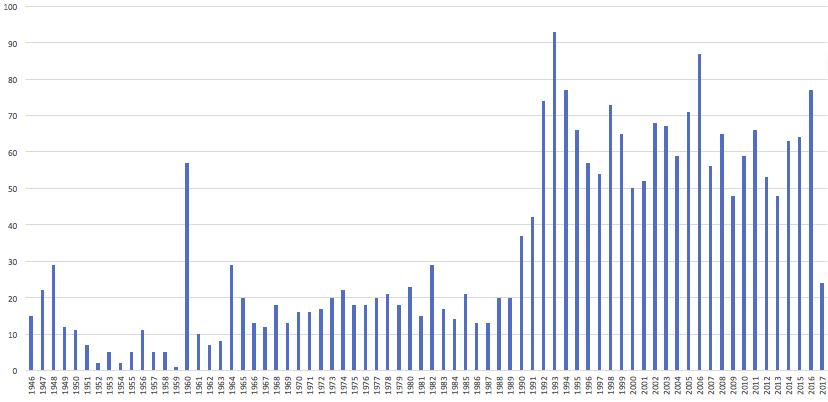
Here is a bar chart of resolutions by year constructed from a pivot table in Excel:
Apart from the general increase in the rate of resolutions produced in the 1990s, 1960 stands out as an outlier. It turns out that our data has duplicate records in it. We will discuss this in the next episode.
References
Key Points
Data that is relatively well structured (in a table) is relatively easily to scrape.
More often than not, web scraping tools need to be told what to scrape.
CSS selectors can be used to define what information to scrape, and how to structure it.
CSS selectors in scrapers need to be designed careful, as the selector chosen for one page may not work perfectly on another.
More advanced data cleaning operations are best done in a subsequent step.